开源库 parallel-hashmap 介绍:高性能 线程安全 内存友好的哈希表 和 btree
文章目录
1. 背景
后台开发很常见一大类需求是 线程安全 高性能 容器数据结构 开源的 https://github.com/greg7mdp/parallel-hashmap parallel-hashmap 是对 Google 的 abseil-cpp 库的改进,可供开发中直接使用。
参考官网的英文文档,简单翻译介绍如下:
[TOC]
2. 概览
parallel-hashmap 提供了一组卓越的 hash map 实现, 和 可以替代 std::map 和 std::set 的 btree 实现,并有如下特点:
-
Header only: 无需链接。直接 include 头文件即可用。
-
drop-in replacement for
std::unordered_map,std::unordered_set,std::mapandstd::set。 原样替换,api 完全兼容标准 stl 容器 。 -
要求支持 C++11 的编译器 , 并且提供 C++14 和 C++17 的 API (例如
try_emplace) -
Very efficient, 明显比编译器默认提供的 unordered map/set 快, 也比 boost 的实现快,比 sparsepp 快。这里有个 benchmark : https://martin.ankerl.com/2019/04/01/hashmap-benchmarks-01-overview/ ,大概 比 std::unorder_map 就是 insert快1倍,find 快3倍
-
Memory friendly: 低内存占用,尽管略微高于 sparsepp 。 参考 abseil 的数据,https://abseil.io/about/design/btree 目前 64位模式下, libstdc++ 实现的 std::set<int32_t> 对插入的每个value,分配 40 字节, 而 absl::btree_set<int32_t> 对每个 value 分配 ~4.3 至 ~5.1 字节
-
支持 heterogeneous lookup
-
很容易前向声明 forward declare: 只需要在头文件中 include
phmap_fwd_decl.h来声明 Parallel Hashmap 容器就行 [注: 目前这种对包含指针作为 key 的哈希表不适用。] -
Dump/load 特性: 当一个
flat哈希表存储了std::trivially_copyable的数据时, 表可以被 dump 到磁盘文件,并作为一个简单的数组高效地 restore 恢复,并且过程中不需要进行 hash 计算。这通常比逐个元素地序列化到磁盘快 10倍,但是会额外占用 10% - 60% 的磁盘空间。 见examples/serialize.cc. (flat hash map/set only) -
Tested 在这些平台上经过了测试: Windows (vs2015 & vs2017, vs2019, Intel compiler 18 and 19), linux (g++ 4.8.4, 5, 6, 7, 8, clang++ 3.9, 4.0, 5.0) 和 MacOS (g++ and clang++) - click on travis and appveyor icons above for detailed test status.
-
自动支持 boost 的 hash_value() 方法,用来提供哈希函数 (见
examples/hash_value.h). 并且提供std::pair和std::tuple的哈希函数实现. -
natvis visualization support in Visual Studio (hash map/set only)
3. 快速 和 内存友好
作者有个介绍文章 讲解了 Parallel Hashmap 的设计和好处.
总结起来说,Google absl 的 flat_hash_map 由于采用 2倍的内存增长 resize 策略,所以有个内存占用的尖峰 peak, 在尖峰时刻,需要3倍的临时内存占用,来把旧的 bucket 里面的数据移动到 新的2倍大的 bucket 里面。
文章提出的想法就是,把一个大的 flat_hash_map 拆分成2的倍数个比如 16个,这样内存峰值就只有原来的 1/16 了。
并且这种拆分还便于进行并发。
本库提供的 hashmap 和 btree 基于 Google 在 Abseil 库中开源的实现。 hashmap 使用了 closed hashing,就是 value 直接存成一个内存数组,避免内存间接访问。通过使用并发的 SSE2 指令,这些 hashmap 可以允许一次并发查找 16 个槽位,即使当 hashmap 的填充率已经达到 87.5% ,也可以保持快速。
重要: 本仓库借鉴了 abseil-cpp 仓库的代码, 做了修改,并且可能和原版本行为不同。本仓库是独立工作,像其他开源项目一样不提供保证。请访问 abseil-cpp 获取官方的 Abseil 库。
4. 安装
无需安装,代码里面直接 include 就行。
5. 例子
|
|
6. 提供的各种哈希表及其优缺点
头文件 parallel_hashmap/phmap.h 提供下列 8 种 哈希表 :
- phmap::flat_hash_set
- phmap::flat_hash_map
- phmap::node_hash_set
- phmap::node_hash_map
- phmap::parallel_flat_hash_set
- phmap::parallel_flat_hash_map
- phmap::parallel_node_hash_set
- phmap::parallel_node_hash_map
头文件 parallel_hashmap/btree.h 提供一下基于 btree 的有序容器 ordered containers:
- phmap::btree_set
- phmap::btree_map
- phmap::btree_multiset
- phmap::btree_multimap
btree 容器是直接移植了 Abseil,因此应该是 Abseil 的表现一样,除了细微不同(例如支持 std::string_view 而不是 absl::string_view,并且有前向声明)
当 btree 被修改,value 可能在内存中被移动。这意味着当 btree 容器被修改时,指向 btree 容器中的 value 的指针或者迭代器会失效。 这和 std::map / std::set 显著不同, std 容器提供指针稳定性的保证。 ‘flat’ hash map 和 set 也会有这种失效。
全部的类型和模板参数可以在这个头文件看到: parallel_hashmap/phmap_fwd_decl.h , 这个头文件也可以用于前向声明 Parallel Hashmap 库。
哈希容器的关键设计点
-
名字包含
flat的哈希表内部会移动 key 和 value,所以如果在外部包含了指向flat哈希表中元素的指针,当哈希表被修改时,指针可能会变成野指针。而名字包含node的哈希表内部不会移动 key 和 value,可以用在这种场合。 -
flat系列哈希表内存占用更少,并且通常比node系列哈希表更快,所以尽可能使用flat系列。当然,例外情况是 value 很大(比如大于 100字节),在内存中移动时很慢的话,此时应使用node系列。 -
parallel系列的哈希表。当你需要在少数个哈希表中存储非常大量的 value 时, 应该优先用parallel系列 哈希表。而如果你需要在大量 哈希表中,每个存储相对少量的元素时,优先用非parallel系列的哈希表。 -
parallel系列哈希表的好处是:
a. 减少了 resize 时候内存占用的峰值。
b. 可以打开多线程支持 (由于内部拆分成多个子哈希表,所以可以借此实现并发安全。)
btree 系列容器中的关键设计
Btree 系列容器是有序容器,可以作为
std::map 和 std::set 的替代。他们在每个树节点中存储多个value,因此更缓存友好,并且内存占用显著更低。
通常都应该优先用 Btree 容器,来代替 STL 中默认的红黑树容器。也有例外:
- 要求指针稳定性,或者迭代器稳定性。
- value 类型巨大,在内存中移动起来比较昂贵。
当不需要顺序的时候, 通常哈希表容器是比 btree容器 更好的选择。
7. 对 Abseil’s 哈希表的改动
-
默认哈希,从 absl::hash 改成了 std::hash。 可以通过定义宏
PHMAP_USE_ABSL_HASH改变。 -
erase(iterator)和erase(const_iterator)都返回指向被删除的元素的下一个元素的迭代器,和 std::unordered_map 一样. 并提供了一个非标准的void _erase(iterator),用于不需要返回 value 的场合。 -
没有提供
absl::string_view这种新类型。std::hash<>支持的所有类型 phmap 都支持 (如果编译器提供了std::string_view那 phmap 当然也支持). -
Abseil 哈希表内部会随机初始化一个哈希种子,这样迭代顺序就是非确定性的,当哈希表被用于面向用户的 web 服务场合的时候,这可以用于阻止 Denial Of Service 攻击,但是这使得调试变困难了。 phmap 哈希表默认不会实现这种随机初始化,但可以通过在 include
phmap.h之前 定义宏#define PHMAP_NON_DETERMINISTIC 1来打开这种随机初始化 (参考 raw_hash_set_test.cc). -
和 Abseil 哈希表不一样, 我们内部做了 哈希值的混合。这在用户提供的哈希函数熵分布比较差的时候, 可以避免哈希表出现严重性能下降。这代理的性能开销是非常低的,并且在使用 不完美 的哈希函数的时候, 也能提供稳定的性能。
8. 内存使用
| type | memory usage | additional peak memory usage when resizing |
|---|---|---|
| flat tables | 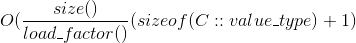 |
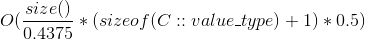 |
| node tables | 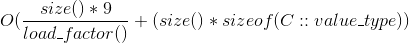 |
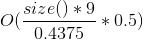 |
| parallel flat tables | |
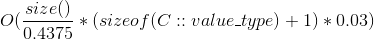 |
| parallel node tables | |
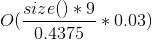 |
- size() 是容器中的 value 数量,通过 size() 方法返回。
- load_factor() 是比例:
size() / bucket_count(). 从 0.4375 (刚 resize 之后) 到 0.875 (在 resize 之前) 之间波动. bucket 数组的大小每次 resize 都 double。 - value 9 来自
sizeof(void *) + 1, 由于对 bucket 数组 中的每一个 entry, node 哈希表存储一个指针加一个字节的元数据, - flat 哈希表存储 value, 加每个value 一个字节的元数据,直接存储在 bucket 数组中,因此得到
sizeof(C::value_type) + 1. - resize 时候的额外峰值内存占用,取决于旧的 bucket 数组的大小(是新bucket数组大小的 0.5倍),就是需要被复制到新bucket数组的 value,并在复制完成后,老的 value 会被释放。
- parallel 哈希表,当用模板参数 N=4 时, 创建 16 个 submap. 当哈希值均匀分布,并在单线程模式下, 任何时间点都只有一个 submap 做 resize,因此比值约等于
0.03即0.5 / 16
9. 哈希表容器的 Iterator 迭代器失效
规则和 std::unordered_map 相同。
| Operations | Invalidated |
|---|---|
| All read only operations, swap, std::swap | Never |
| clear, rehash, reserve, operator= | Always |
| insert, emplace, emplace_hint, operator[] | Only if rehash triggered |
| erase | Only to the element erased |
10. btree 容器的 Iterator 失效
不同于 std::map 和 std::set, 任何修改操作都可能使得存活的迭代器失效。
| Operations | Invalidated |
|---|---|
| All read only operations, swap, std::swap | Never |
| clear, operator= | Always |
| insert, emplace, emplace_hint, operator[] | Yes |
| erase | Yes |
11. Example 2 - 为用户自定义类提供 hash 函数
为了使用 flat_hash_set 或者 flat_hash_map,自定义类需要提供一个 哈希函数。可以通过以下2种方法之一实现:
-
通过 HashFcn 模板参数提供一个 hash 函数
-
使用 boost 的话,可以在自定义类中加一个
hash_value()friend 函数.
例子自己看官方文档吧, 就不贴了。
12. 线程安全性
Parallel Hashmap 容器遵循 C++ 标准库的线程安全规则。具体地:
-
单个 phmap 哈希表从多个线程读,是线程安全的。例如,给定一个哈希表 A,从 thread 1 和 thread 2 并发读是安全的。
-
如果单个哈希表在被一个线程写,在任何线程进行的,对该哈希表的读写操作,都是不安全的,需要被保护。例如,给定哈希表 A, 如果 thread 1 在写 A, 比如避免 thread 2 在同时读或者写 A。
-
不同线程对同一种 type 的不同实例,并发进行读写,是安全的。例如,给定相同类型的哈希表 A 和 B , 在 thread 1 中写 A, 并且在 thread 2 中读 B ,是安全的。
-
parallel 系列的哈希表,可以通过提供一个 synchronization type (例如 std::shared_mutex, boost::shared_mutex, std::mutex, ) 作为模板的最后一个参数, 变成读写操作内部线程安全的。因为内部是在 submap 子哈希表上进行了加锁,可以获得一种较大的并发水平。读操作可以通过
if_contains()安全地进行, 通过持有 submap 的锁,并把 value 的引用传给回调函数。类似地, 用modify_if或try_emplace_l可以进行安全的写操作。但是要注意,标准 API 返回的迭代器或者引用并没有被 mutex 保护,所以当另一个线程可能修改哈希表时,不能可靠地使用他们。 -
如果使用各种 mutex 类型的例子,包括 boost::mutex, boost::shared_mutex 和 absl::Mutex 可以参考
examples/bench.cc(推荐使用 C++17 的 std::shared_mutex ,因为实测性能最好)
parallel_系列容器的线程安全的函数有:
- insert()
- emplace()
- lazy_emplace()
- erase()
- merge()
- swap()
- rehash()
- find()
- bucket_count()
- has_element()
- if_contains()
- modify_if()
- try_emplace_l()
多线程的例子,例如
|
|
我的博客即将同步至腾讯云+社区,邀请大家一同入驻:(https://cloud.tencent.com/developer/support-plan?invite_code=3qw4g1gk0xgkc)